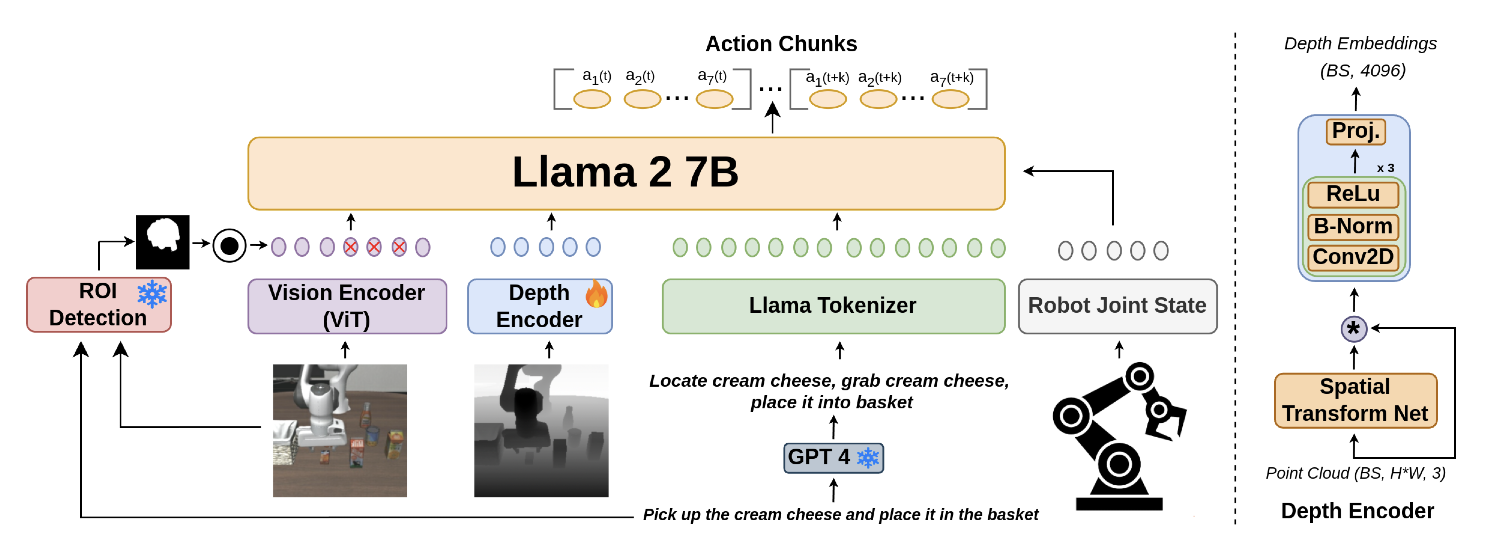
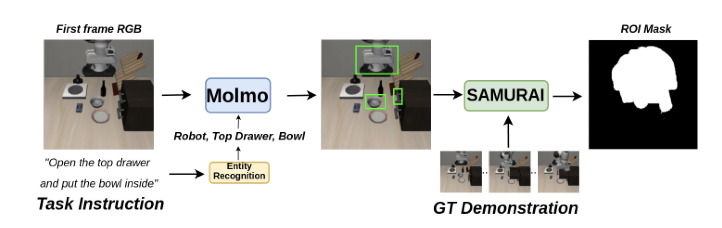
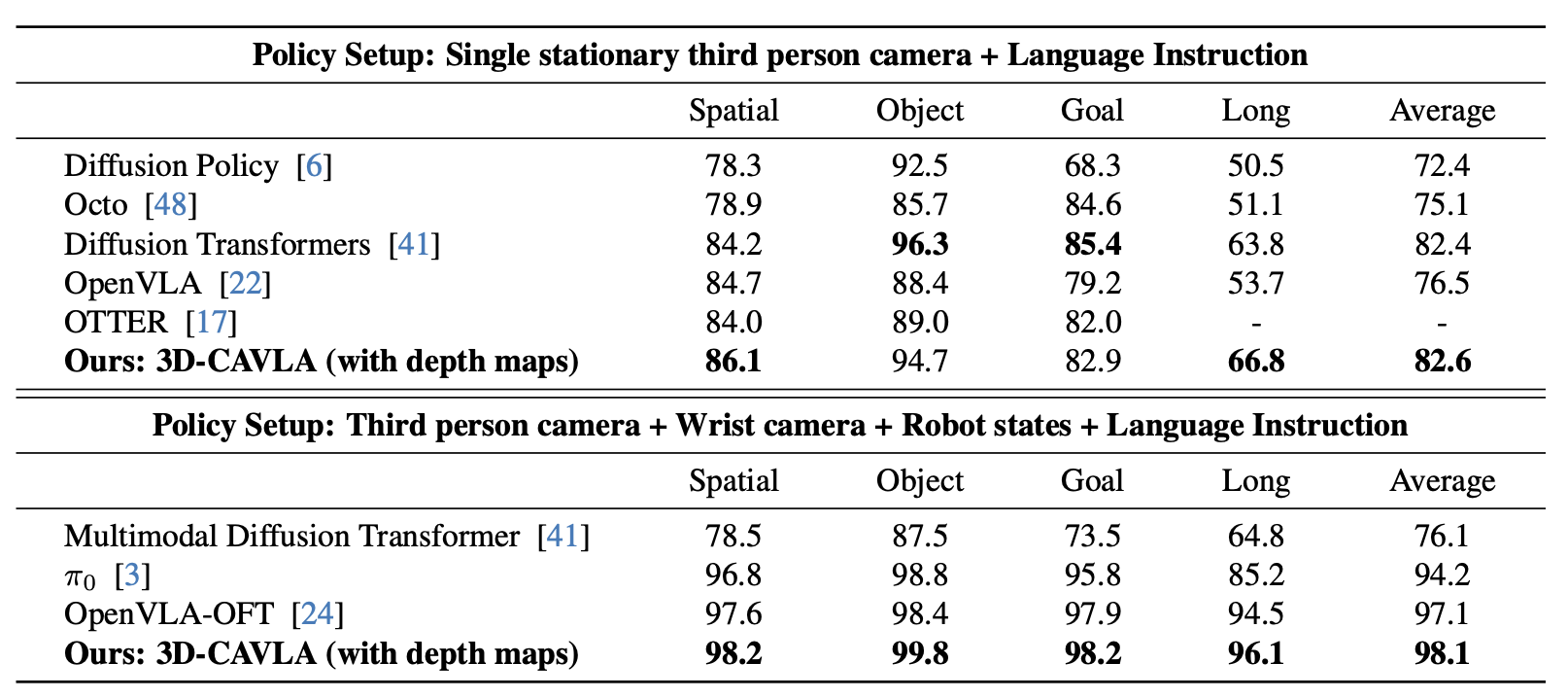
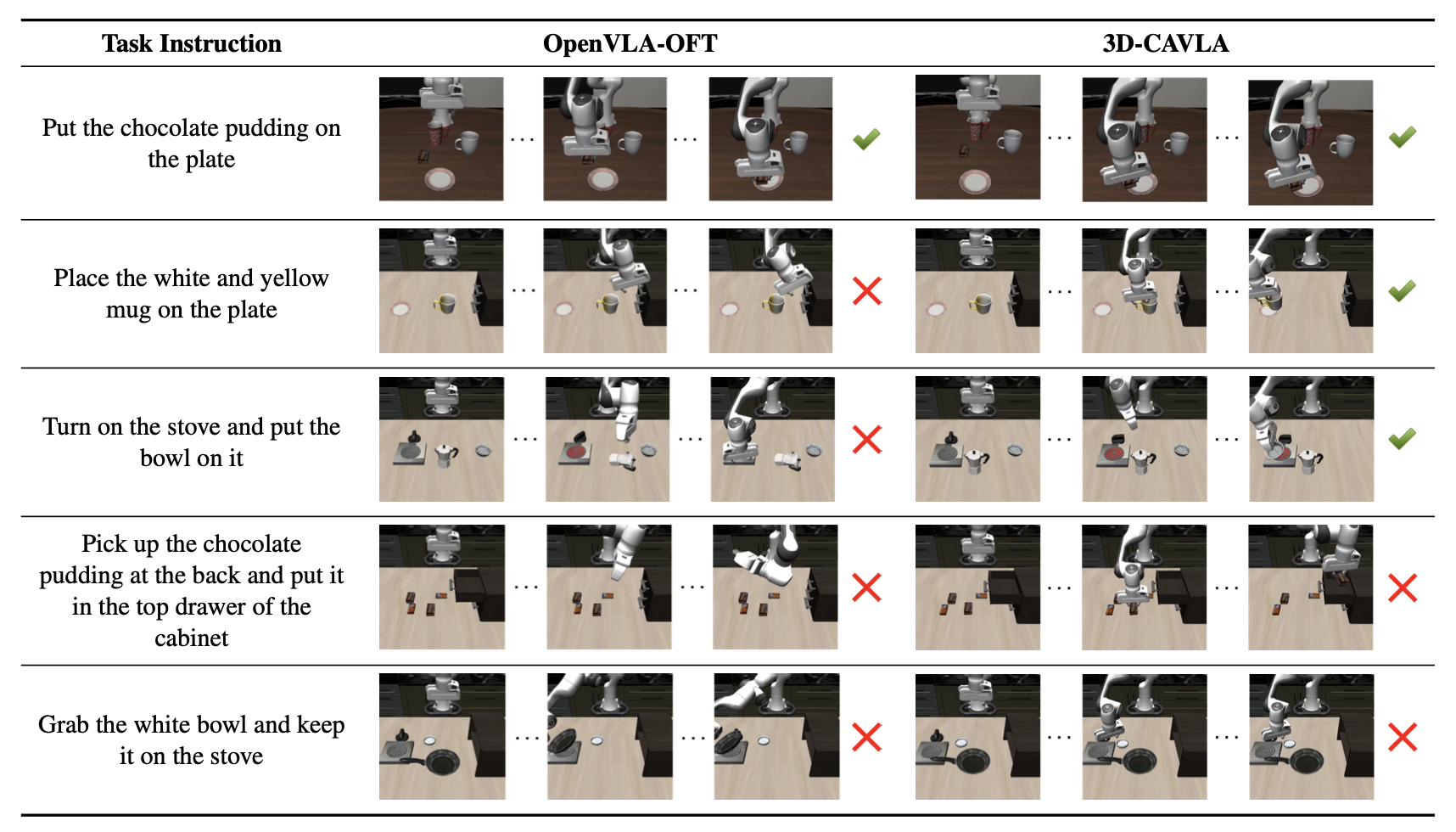
Robotic manipulation in 3D requires learning an N degree-of-freedom joint space trajectory of a robot manipulator. Robots must possess semantic and visual perception abilities to transform real-world mappings of their workspace into the low-level control necessary for object manipulation. Recent work has demonstrated the capabilities of fine-tuning large Vision-Language Models (VLMs) to learn the mapping between RGB images, language instructions, and joint space control. These models typically take as input RGB images of the workspace and language instructions, and are trained on large datasets of teleoperated robot demonstrations. In this work, we explore methods to improve the scene context awareness of a popular recent Vision-Language-Action model by integrating chain-of-thought reasoning, depth perception, and task-oriented region of interest detection. Our experiments in the LIBERO simulation environment show that our proposed model, 3D-CAVLA, improves the success rate across various LIBERO task suites, achieving an average success rate of 98.1%. We also evaluate the zero-shot capabilities of our method, demonstrating that 3D scene awareness leads to robust learning and adaptation for completely unseen tasks. 3D-CAVLA achieves an absolute improvement of 8.8% on unseen tasks. We open-source our code and the unseen tasks dataset we created to promote community-driven research: